在當(dāng)今大數(shù)據(jù)處理領(lǐng)域,Apache Spark以其卓越的內(nèi)存計(jì)算能力和靈活的編程模型,成為眾多企業(yè)數(shù)據(jù)處理與分析的首選框架。要充分發(fā)揮Spark的性能潛力,避免資源浪費(fèi)與作業(yè)延遲,深入理解并實(shí)施有效的性能調(diào)優(yōu)至關(guān)重要。性能調(diào)優(yōu)主要圍繞兩個(gè)核心維度展開(kāi):開(kāi)發(fā)調(diào)優(yōu)與資源調(diào)優(yōu),兩者相輔相成,共同構(gòu)建高效、穩(wěn)定的Spark應(yīng)用。
一、 開(kāi)發(fā)調(diào)優(yōu):編寫高效的Spark代碼
開(kāi)發(fā)調(diào)優(yōu)聚焦于應(yīng)用程序代碼層面,旨在通過(guò)優(yōu)化數(shù)據(jù)處理邏輯、選擇合適API和算法來(lái)提升執(zhí)行效率。
- 避免創(chuàng)建重復(fù)的RDD:對(duì)同一份數(shù)據(jù)源,應(yīng)盡可能復(fù)用已創(chuàng)建的RDD,而非多次讀取,以減少不必要的I/O開(kāi)銷和計(jì)算重復(fù)。
- 對(duì)多次使用的RDD進(jìn)行持久化(緩存):當(dāng)一個(gè)RDD被多次行動(dòng)操作(如
count,collect)使用時(shí),應(yīng)使用persist()或cache()方法將其持久化到內(nèi)存或磁盤。這可以避免Spark從源頭重新計(jì)算該RDD,大幅提升性能。選擇正確的持久化級(jí)別(如MEMORY<em>ONLY,MEMORY</em>AND_DISK)是關(guān)鍵。 - 盡量避免使用Shuffle操作:Shuffle(如
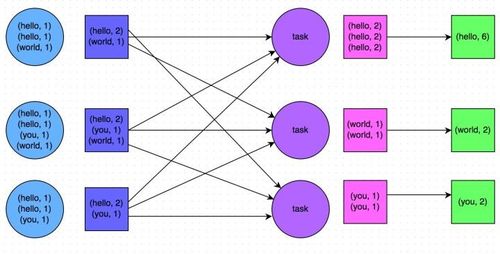
reduceByKey,join,groupByKey)涉及大量跨節(jié)點(diǎn)的數(shù)據(jù)混洗與網(wǎng)絡(luò)傳輸,是性能瓶頸的主要來(lái)源。應(yīng)優(yōu)先使用reduceByKey(在Map端先進(jìn)行合并)替代groupByKey,并考慮使用broadcast join(廣播小表)來(lái)避免大表間的Shuffle Join。 - 使用高性能算子:例如,用
mapPartitions替代普通的map,以減少函數(shù)調(diào)用開(kāi)銷;用foreachPartitions替代foreach來(lái)優(yōu)化數(shù)據(jù)寫入外部系統(tǒng)的操作。 - 使用Kryo序列化:Spark默認(rèn)使用Java序列化,效率較低且序列化后的數(shù)據(jù)體積較大。通過(guò)配置使用Kryo序列化(
spark.serializer設(shè)置為org.apache.spark.serializer.KryoSerializer并注冊(cè)自定義類),可以顯著減少序列化時(shí)間和網(wǎng)絡(luò)傳輸?shù)臄?shù)據(jù)量。 - 優(yōu)化數(shù)據(jù)結(jié)構(gòu):盡量使用Scala的原生類型(如
Int,Long)和字符串,以及基于數(shù)組的數(shù)據(jù)結(jié)構(gòu),減少Java/Scala對(duì)象帶來(lái)的內(nèi)存開(kāi)銷。
二、 資源調(diào)優(yōu):合理分配與利用集群資源
資源調(diào)優(yōu)關(guān)注如何為Spark作業(yè)分配合適的硬件資源(CPU、內(nèi)存、磁盤、網(wǎng)絡(luò)),確保作業(yè)能夠高效、穩(wěn)定地運(yùn)行。這通常通過(guò)Spark的配置參數(shù)來(lái)實(shí)施。
- Executor配置:
spark.executor.memory:設(shè)置每個(gè)Executor進(jìn)程的內(nèi)存大小。需要綜合考慮存儲(chǔ)內(nèi)存(緩存RDD)和執(zhí)行內(nèi)存(任務(wù)計(jì)算),通常建議占總節(jié)點(diǎn)內(nèi)存的60%-75%,并留出部分給操作系統(tǒng)和其他服務(wù)。
spark.executor.cores或spark.executor.cores:設(shè)置每個(gè)Executor使用的CPU核心數(shù)。這決定了每個(gè)Executor中并行運(yùn)行的任務(wù)數(shù)(spark.task.cpus默認(rèn)為1)。通常,一個(gè)Executor配置3-5個(gè)核心能在并行度和垃圾回收(GC)效率間取得較好平衡。
spark.executor.instances:指定啟動(dòng)的Executor數(shù)量。可以通過(guò)總核心數(shù)除以每個(gè)Executor的核心數(shù)來(lái)估算。
- Driver配置:
spark.driver.memory:設(shè)置Driver進(jìn)程的內(nèi)存,當(dāng)需要收集大量數(shù)據(jù)到Driver端(如collect操作)或使用廣播變量時(shí),需要適當(dāng)調(diào)大。
- 并行度與分區(qū)調(diào)優(yōu):
spark.default.parallelism:對(duì)于Shuffle操作的默認(rèn)并行度(分區(qū)數(shù)),建議設(shè)置為集群總核心數(shù)的2-3倍。
spark.sql.shuffle.partitions:Spark SQL中Shuffle操作的分區(qū)數(shù),默認(rèn)200,在處理大數(shù)據(jù)量時(shí)通常需要調(diào)大。
- 在讀取數(shù)據(jù)后或進(jìn)行Shuffle操作前,可以使用
repartition()或coalesce()主動(dòng)調(diào)整RDD/DataFrame的分區(qū)數(shù),使其與可用計(jì)算資源匹配,避免數(shù)據(jù)傾斜或分區(qū)過(guò)小導(dǎo)致的調(diào)度開(kāi)銷。
- 內(nèi)存管理:
- 理解Spark的統(tǒng)一內(nèi)存管理模型(執(zhí)行內(nèi)存與存儲(chǔ)內(nèi)存共享統(tǒng)一區(qū)域,并可互相借用),根據(jù)作業(yè)特性(是計(jì)算密集型還是緩存密集型)調(diào)整
spark.memory.fraction(默認(rèn)0.6)和spark.memory.storageFraction(默認(rèn)0.5)。
- Shuffle調(diào)優(yōu):
spark.shuffle.file.buffer:增大Shuffle寫操作的緩沖區(qū)(默認(rèn)32k),可以減少磁盤I/O次數(shù)。
spark.reducer.maxSizeInFlight:增大Reducer每次拉取數(shù)據(jù)的緩沖區(qū)(默認(rèn)48m),可以減少網(wǎng)絡(luò)請(qǐng)求次數(shù)。
spark.shuffle.io.maxRetries與spark.shuffle.io.retryWait:調(diào)整Shuffle過(guò)程中網(wǎng)絡(luò)連接失敗的重試策略,在網(wǎng)絡(luò)不穩(wěn)定的環(huán)境中可能需調(diào)整。
三、 計(jì)算機(jī)軟硬件技術(shù)基礎(chǔ)
有效的Spark調(diào)優(yōu)離不開(kāi)對(duì)底層計(jì)算機(jī)軟硬件技術(shù)的理解:
- 硬件層面:需要關(guān)注CPU核心數(shù)、內(nèi)存容量與帶寬、磁盤類型(SSD/HDD)與I/O性能、網(wǎng)絡(luò)帶寬。例如,使用SSD可以加速Shuffle和緩存落盤;萬(wàn)兆網(wǎng)絡(luò)可以減少Shuffle的數(shù)據(jù)傳輸時(shí)間。
- 軟件與系統(tǒng)層面:選擇合適的JVM版本并進(jìn)行GC調(diào)優(yōu)(如使用G1垃圾回收器);合理配置操作系統(tǒng)參數(shù)(如文件句柄數(shù)、網(wǎng)絡(luò)緩沖區(qū));在YARN或Kubernetes等資源管理器上運(yùn)行時(shí),需理解其資源調(diào)度機(jī)制并與Spark參數(shù)配合。
****
Spark性能調(diào)優(yōu)是一個(gè)迭代和權(quán)衡的過(guò)程。最佳實(shí)踐通常是從開(kāi)發(fā)調(diào)優(yōu)入手,編寫高效、簡(jiǎn)潔的代碼,減少不必要的計(jì)算和數(shù)據(jù)移動(dòng)。然后,基于作業(yè)的實(shí)際運(yùn)行特征和集群資源狀況,進(jìn)行針對(duì)性的資源參數(shù)調(diào)優(yōu)。借助Spark Web UI等工具監(jiān)控作業(yè)執(zhí)行情況(如Stage耗時(shí)、Shuffle數(shù)據(jù)量、GC時(shí)間),是定位瓶頸、持續(xù)優(yōu)化不可或缺的一環(huán)。通過(guò)將高效的編程模式與合理的資源配置相結(jié)合,才能最大化挖掘Spark與硬件基礎(chǔ)設(shè)施的潛力,實(shí)現(xiàn)數(shù)據(jù)處理任務(wù)的高性能與高穩(wěn)定性。